An Apologist's Defense of Trunk-based Development
There are two prevailing thoughts about source code management in contemporary software development with multi-member teams: trunk-based development and the feature branch model (or pull-request model). Looking at GitHub alone will surly lead you to believe that the only way to develop with a distributed source control system is using the pull-request model, but then there are technology pundits out there who opine that the only way to use git (or one of its relatives) is using the trunk based development model.
This disparity (the masses using one model, but the role-models prescribing another) has understandably led to confusion in the tech industry. After reading Martin Fowler’s excellent description of Trunk Based Development (which he refers to as it’s more classical, but now overloaded, terminology: Continuous Integration) I found a few bloggers that didn’t like Martin Fowler’s suggestions. I’m going to address the article found here by James McKay (whom I will refer to as JM). I will attempt to assuage some of their concerns and answer some of the questions they have in this post.
Continuous Integration is At Odds With Feature Branching
The first point that JM brings up is, “[Martin Fowler and Mike Mason] are saying that Feature Branching is incompatible with Continuous Integration.” I believe that the source of the confusion here is simply a case of semantics and history.
Continuous Integration (as I eluded to previously) has multiple meanings today. The history of the term is described very well on Wikipedia, but it would do well to quote the opening line, “Continuous integration (CI) is the practice, in software engineering, of merging all developer working copies with a shared mainline several times a day.” As you can see its original meaning had nothing to do with build servers, but various vendors coopted the term (quite successfully) and the original meaning is lost on some developers. Continuous Integration originally meant just that—integrating continuously. Integrating all the new code you wrote as frequently as you can with what is the latest code on a single branch. Everyone has the same version of the latest code. With Feature Branching you don’t share this promise. Everyone may have the latest code from a shared branch, but they also have their own dirty little secrets which none of the other branches share.
Git and Mercurial often show a representation of a commit history something like this for feature branches:
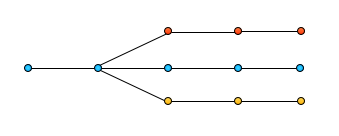
The blue branch in the middle is the shared, common, dev, develop, whatever-you-want-to-call-it branch. The plan is to release whatever is on the blue branch. The red and yellow branches are feature branches that have branched off of the blue branch. Unfortunately this image is misleading. The red and yellow branches may be merging frequently with the blue branch, but they aren’t as close to each other as they may seem. The red and yellow branches are actually drifting further and further apart. Something like the next image:
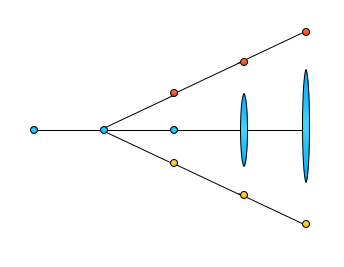 The blue branch, which is still getting commits (presumably from other branches) is still the same distance from both red and yellow, but red and yellow are much further apart., The more code that is added to red but not to yellow or to yellow but not to red the more different they become. The longer time goes without merging the code from red and yellow together (as well as any other feature branches) the further apart they two branches will drift, even if they are continually merging with blue.
The blue branch, which is still getting commits (presumably from other branches) is still the same distance from both red and yellow, but red and yellow are much further apart., The more code that is added to red but not to yellow or to yellow but not to red the more different they become. The longer time goes without merging the code from red and yellow together (as well as any other feature branches) the further apart they two branches will drift, even if they are continually merging with blue.
This leads us to a natural question about what happens when one of these branches merges with the shared blue branch. I’m glad you asked, I’ve got an image for that:
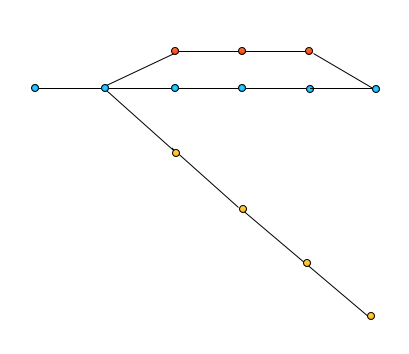
In the third image you see that the yellow branch is nowhere near where the blue branch is anymore. In fact it is further from blue than when it started because now the blue branch is also the red branch and so yellow is actually as far away from its parent as it was from the red branch.
This will remain the case until a merge occurs which will likely cause a huge merge conflict and while merge conflicts would happen even when using trunk based development, they occur are more regulated and more manageable intervals (more on that later).
Obviously this is an image and I haven’t calculated the actual difference between the red and yellow branches, theoretically this could be done with an algorithm that tracked differences, but the point is clear: when using feature branches you are often in danger of working on a branch that is very different from the other feature branches and when one of them merges before your branch merges then you will have to deal with the problem of finding out how to merge the two very different code bases together.
The problem highlighted is known as delayed integration which, just like it sounds, is exactly the opposite of Continuous Integration and means that the developers involved have waited to integrate their code with others’ code. That’s why feature branches are at odds with Continuous Integration, because they are nothing alike.
Merging Isn't So Bad
JM declares that they didn’t feel that merging was so bad (maybe not is so many words). They’re right. But it is dangerous, and in more ways than one. In fact there are three ways that merging is dangerous. The first is obvious, the developer preforming the merge may make a mistake. Maybe they misunderstood the other developer’s code or they could have forgotten exactly what that piece of code was supposed to do. It’s true that this is a problem that can be retroactively rectified, but it’s still inconvenient.
The second is a little less obvious and doesn’t have anything to do with the actual merge process, but in the fact that merging must wait. The problem arrises when you have to wait to share code! Just the other day I overheard two developers talking. One of them needed some code that the other had written, but they were working in two different branches. They spent probably ten minutes thinking of ways to get Git to share parts of one branch with the other, but not merging the whole branch.
The last way that merging is dangerous is because it gets more difficult with time. I like to think of it as gum on a sidewalk. If someone spits gum on the sidewalk (it wasn’t you, of course, because it is a nasty habit) it’s really quite easy to get it off the ground and into a trash bin. But if you wait a week, chances are that it has been stepped on and trampled and it will take a long time to get it off (unless you have a high-powered presser washer handy).
Merging little changes (like you do with trunk based development) is usually painless, but the longer you let changes go without merging them the greater the chance that you code will be more difficult to merge. This is one of the best features of Trunk Based Development: small merges, frequently.
Feature Toggles
There seems to be a lot of fear about feature toggles. Whether it done using branch by abstraction or permissions or some other method it’s basically a method to not call new code until the time comes when it is ready to turn them on. JM feels that feature toggling is actually more dangerous than keeping code completely isolated until it is ready to be used and I respect this fear. It’s true that there is a small amount of risk involved when toggling a feature that isn’t ready yet. But I want to point out a misunderstanding that he has and a benefit that feature toggles have that you wouldn’t get when using feature branches.
First, James McKay says that feature branches is releasing code that is untested. This is untrue. We must keep in mind that trunk based development isn’t just a pattern for the repository—it is a pattern for the way we code as well. In trunk based development one never pushes code that hasn’t passed every unit test and doesn’t have unit test written for it as well. If you are careful, end users should never be running the code that isn’t ready, but if by some small chance they do it should be tested. (I don’t have time to get into the classic unit tests vs the mockist approach, but there are differences of opinion about that in the software development world too. I believe that if unit tests are written using the classic approach, which is a manner that test more consistently with how a user may be using or misusing your system, then those tests will be more than adequate at preventing bugs in feature toggled software without manual tests of any kind.)
The other benefit to using feature toggles comes into play when everything is working as designed, but you want to turn a feature off for a business reason. Maybe you are using a social network’s Oauth 2 authentication to login to your site, but then a competitor acquires them and you want to turn off everything in your site associated with them. If you’ve been using feature toggles this becomes a simple matter of reenabling the toggle that was in place—if not, you may need to go in and manually remove all traces by hand (introducing the chance for bugs and errors that wouldn’t have happened if you used a configuration or abstraction to keep a feature from being released). Of course this means whatever mechanism you are using to do your feature toggles can be reenabled and hasn’t been removed, but chances are good that it’s easier to reenable a feature toggle than to remove and replace code by hand.
Whatever Merge Goes
I’ve compared and contrasted two version control models, Trunk Based Development and Feature Branches. There is, however, a third option that gets some usage. Unfortunately this model sometimes gets confused with Trunk Based Development, but the two are very different. There isn’t really an official name for it, but I like to call it Whatever Merge Goes meaning a haphazard, non-regulated method for software version control.
It’s confused with Trunk Based Development, because there is usually only one shared branch. The difference is that the trunk branch is treated carelessly. Developers aren’t required to run unit tests before committing and pushing code or to even write them. Stories are not polished before developers are expected to work with them (and the developers almost never helped define them) and so there is real risk that the features committed to for a coding cycle may only get half-way done by the deadline and won’t be able to be removed which will result in a traffic jam of last minute changes and half-tested code.
Please don’t confuse a team working on a single shared branch with Trunk Based Development. Trunk Based Development requires discipline and diligence. Adequate tests, discipline to run them and verify the build won’t break, and frequent pushes (not just when your code if finished but when it’s in a stable state) and pulls are all a vital part of Trunk Based Development. Between having no process and having Feature Branches, I’d choose Feature Branches too even though that will only go so far to improve the situation.
When to Choose Feature Branches
In all professionally developed projects I would use Trunk Based Development. With personal projects (where you or a small group of friends are working on an application) I’d use Trunk Based Development. The only time I would consider branching is when I was working with an open source project and didn’t know if I could trust the other developers contributing.
For an excellent resource regarding Trunk Based Development refer to Paul Hammant’s blog, he has several articles talking about what Trunk Based Development is, why it’s better, and about how companies like Facebook and Google use Trunk Based Development.